Process Switching
Process switching, also referred to as software switching or slow path, is a switching mechanism in which the general-purpose CPU on a router is in charge of packet switching. In IOS, the ip_input process runs on the general-purpose CPU for processing incoming IP packets. Process switching is the fallback for CEF because it is dedicated to processing punted IP packets when they cannot be switched by CEF.
The types of packets that require software handling include the following:
Packets sourced or destined to the router (using control traffic or routing protocols)
Packets that are too complex for the hardware to handle (that is, IP packets with IP options)
Packets that require extra information that is not currently known (for example, ARP)
Figure 1-6 illustrates how a packet that cannot be CEF switched is punted to the CPU for processing. The ip_input process consults the routing table and ARP table to obtain the next-hop router’s IP address, outgoing interface, and MAC address. It then overwrites the destination MAC address of the packet with the next-hop router’s MAC address, overwrites the source MAC address with the MAC address of the outgoing Layer 3 interface, decrements the IP time-to-live (TTL) field, recomputes the IP header checksum, and finally delivers the packet to the next-hop router.
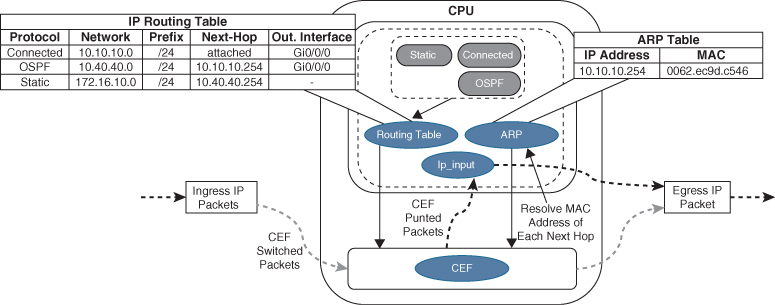
Figure 1-6 Process Switching
The routing table, also known as the >Routing Information Base (RIB), is built from information obtained from dynamic routing protocols and directly connected and static routes. The ARP table is built from information obtained from the ARP protocol.
Cisco Express Forwarding
Cisco Express Forwarding (CEF) is a Cisco proprietary switching mechanism developed to keep up with the demands of evolving network infrastructures. It has been the default switching mechanism on most Cisco platforms that do all their packet switching using the general-purpose CPU (software-based routers) since the 1990s, and it is the default switching mechanism used by all Cisco platforms that use specialized application-specific integrated circuits (ASICs) and network processing units (NPUs) for high packet throughput (hardware-based routers).
The general-purpose CPUs on software-based and hardware-based routers are similar and perform all the same functions; the difference is that on software-based routers, the general-purpose CPU is in charge of all operations, including CEF switching (software CEF), and the hardware-based routers do CEF switching using forwarding engines that are implemented in specialized ASICs, ternary content addressable memory (TCAM), and NPUs (hardware CEF). Forwarding engines provide the packet switching, forwarding, and route lookup capability to routers.
Ternary Content Addressable Memory
A switch’s ternary content addressable memory (TCAM) allows for the matching and evaluation of a packet on more than one field. TCAM is an extension of the CAM architecture but enhanced to allow for upper-layer processing such as identifying the Layer 2/3 source/destination addresses, protocol, QoS markings, and so on. TCAM provides more flexibility in searching than does CAM, which is binary. A TCAM search provides three results: 0 for true, 1 false, and X for do not care, which is a ternary combination.
The TCAM entries are stored in Value, Mask, and Result (VMR) format. The value indicates the fields that should be searched, such as the IP address and protocol fields. The mask indicates the field that is of interest and that should be queried. The result indicates the action that should be taken with a match on the value and mask. Multiple actions can be selected besides allowing or dropping traffic, but tasks like redirecting a flow to a QoS policer or specifying a pointer to a different entry in the routing table are possible.
Most switches contain multiple TCAM entries so that inbound/outbound security, QoS, and Layer 2 and Layer 3 forwarding decisions occur all at once. TCAM operates in hardware, providing faster processing and scalability than process switching. This allows for some features like ACLs to process at the same speed regardless of whether there are 10 entries or 500.
Centralized Forwarding
Given the low cost of general-purpose CPUs, the price of software-based routers is becoming more affordable, but at the expense of total packet throughput.
When a route processor (RP) engine is equipped with a forwarding engine so that it can make all the packet switching decisions, this is known as a centralized forwarding architecture. If the line cards are equipped with forwarding engines so that they can make packet switching decisions without intervention of the RP, this is known as a distributed forwarding architecture.
For a centralized forwarding architecture, when a packet is received on the ingress line card, it is transmitted to the forwarding engine on the RP. The forwarding engine examines the packet’s headers and determines that the packet will be sent out a port on the egress line card and forwards the packet to the egress line card to be forwarded.
Distributed Forwarding
For a distributed forwarding architecture, when a packet is received on the ingress line card, it is transmitted to the local forwarding engine. The forwarding engine performs a packet lookup, and if it determines that the outbound interface is local, it forwards the packet out a local interface. If the outbound interface is located on a different line card, the packet is sent across the switch fabric, also known as the backplane, directly to the egress line card, bypassing the RP.
Figure 1-7 shows the difference between centralized and distributed forwarding architectures.
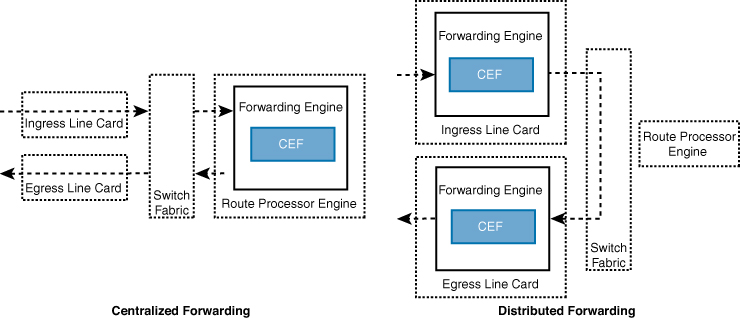
Figure 1-7 Centralized Versus Distributed Forwarding Architectures